


 |
Маєте Телеграм? Два кліки - і ви не пропустите жодної важливої юридичної новини. Нічого зайвого, лише #самасуть. З турботою про ваш час! |
За результатами фонетичної експертизи (дослідження диктора за фізичними параметрами усного мовлення, акустичних сигналів та середовищ) часто вирішується доля людини. На практиці, ми маємо, на жаль, зневажливе ставлення до описової частини таких експертиз з боку суддів, та ще більш зневажливе ставлення з боку експертів. Зараз ми маємо справу з випадком, коли зазначене у висновку експерта викликає регіт, та судді все одно не бачать підстав для призначення повторної експертизи.
Але якщо комусь з юристів все ж таки цікаво, то я спробую максимально зрозуміло пояснити чому, наприклад, виконання вказаної експертизи із застосуванням програмного комплексу Sive Base викликає багато запитань.
Почну з того, що відповідна методика не зареєстрована у Міністерстві юстиції України. Її, так трапилося, взагалі в Україні немає. Зареєстровано тільки методичні рекомендації, що є лише інструкцією для користувача програми, та навіть вказані рекомендації чомусь для службового користування. Дуже смішно, наприклад, коли експерти пояснюють секретність вказаних рекомендацій. «Мов, начебто, якщо злочинець буде їх знати, він щось змінить у власному голосі у такий спосіб, що зробить проведення експертизи неможливою».
У кожної людини є унікальні фонетичні особливості голосу, вимови та артикуляції. Вони залежать від анатомічних особливостей голосового апарату та мовної практики. Незважаючи на можливі зміни в інтонації чи тембрі голосу, основні артикуляційні та просодичні особливості мовця залишаються відносно стабільними. Якщо б це було не так, то і фонетичної експертизи не існувало б. Ба більше, математичний апарат, що використовується, відомий досить давно. Так, формула відстані Кульбака-Лейблера (Kullback–Leibler divergence, KL-divergence) була розроблена американськими математиками Соломоном Кульбаком (Solomon Kullback) і Річардом Лейблером (Richard Leibler) у 1951 році.
Для того, щоб перевірити описову частину експертного висновку, зрозуміло, потрібна методика у наявності. Інакше, що ми перевіряємо? Ну, скажімо, помилився експерт. Це можливо? Як переконати суд у вказаній помилці, якщо методика невідома? Як суд тоді вникає в описову частину, особливо з урахуванням того, що жодний доказ не має наперед встановленої сили. Тобто наразі практично по всій країні судді звертають увагу лише на висновки експертизи, залишаючи дослідницьку частину поза увагою. Може, тоді і треба, щоб експерт надавав сторонам та суду лише висновки? Бо інакше дуже важко бачити, як дослідження експертизи у суді перетворюється на ганебне явище.
Повернімося до Sive Base. Та хоч методика та методичні рекомендації мені невідомі, але знайомі слова я там знайшов.
Спочатку експерт побудує порівняльну амплітудно-частотну характеристику досліджуваного зразку голосу і мовлення, та «еталонного» зразку. За наслідками такого порівняння він порахує Probability (ймовірність), що чомусь в українському перекладі буде зазначено як «узгодження голосів». Є дуже та дуже просте питання — а взагалі до чого тут теорія ймовірностей? Чи можливо її застосовувати у цьому випадку?
Для того щоб застосувати теорію ймовірностей, подія має бути випадковою, повторюваною, мати визначений простір можливих результатів і підкорятися аксіомам Колмогорова. У цьому випадку, коли ми маємо два зразки голосу та мовлення, яка подія випадкова???? Тому теорія ймовірностей при фонетичному аналізі не застосовується, а застосовується математична статистика.
Чим відрізняється математична статистика від теорії ймовірностей?
|
Характеристика |
Теорія ймовірностей |
Математична статистика |
|---|---|---|
|
Що вивчає? |
Закони випадкових явищ і моделі ймовірностей. |
Методи аналізу даних на основі ймовірності. |
|
Що використовує? |
Абстрактні ймовірнісні моделі. |
Реальні вибірки та статистичні дані. |
|
Тип задач |
Визначення ймовірності подій, очікуваних значень, розподілів випадкових величин. |
Оцінка параметрів, перевірка гіпотез, прогнозування. |
|
Приклад |
Яка ймовірність випадіння "орла" при підкиданні монети? |
Чи впливає зміна реклами на рівень продажів? |
Тобто доволі цікаво, а коли усі причетні до аналізу вказаної експертизи оцінюють результат, що вони розуміють під Probability?
Що цікаво далі. За графіками цих порівнянь можливо, наприклад, зробити формантний аналіз. Форманти — це піки в АЧХ (резонансні частоти голосового тракту). Основні форманти (F1, F2, F3) є стабільними для кожної людини, навіть якщо вона говорить голосніше чи тихіше. На графіку вони виглядають як висота, проведена з піку АЧХ на ось Х. Форманти порівнюються окремо для кожного звука (переважно голосних), оскільки вони є резонансними характеристиками голосового тракту під час вимови певного звука.
Чому аналізують форманти окремо для кожної букви (звука)?
Форманти — це резонанси голосового тракту, а його положення змінюється залежно від звука.
Різні голосні мають різні формантні структури — саме тому ми чуємо їх як різні звуки.
При порівнянні голосів важливо аналізувати однакові звуки — наприклад, якщо порівнювати звук [a] у двох записах, треба дивитися саме на його форманти, а не на випадкові шуми чи інші частотні компоненти.
Приклад (як відрізняються голосні):
-
[ɑ] ("а" у слові father):
-
F1 ≈ 730 Гц, F2 ≈ 1090 Гц, F3 ≈ 2440 Гц
-
-
[i] ("і" у слові meet):
-
F1 ≈ 270 Гц, F2 ≈ 2290 Гц, F3 ≈ 3010 Гц
-
-
[u] ("у" у слові boot):
-
F1 ≈ 300 Гц, F2 ≈ 870 Гц, F3 ≈ 2240 Гц
-
Що ми побачимо на вказаних графіках порівняння АЧХ у Sive Base. Взагалі нічого. Ніяких формант. Та взагалі не зрозуміло, що було проаналізовано? АЧХ взагалі чого — усього файлу? Є якісь дві криві, які мають певну відстань одна від іншої. І так у засіданні усі подивилися на вказані малюнки, та пішли далі. Цікаво, а що потрібно намалювати, щоб це викликало непорозуміння? Фігуру з трьох пальців?
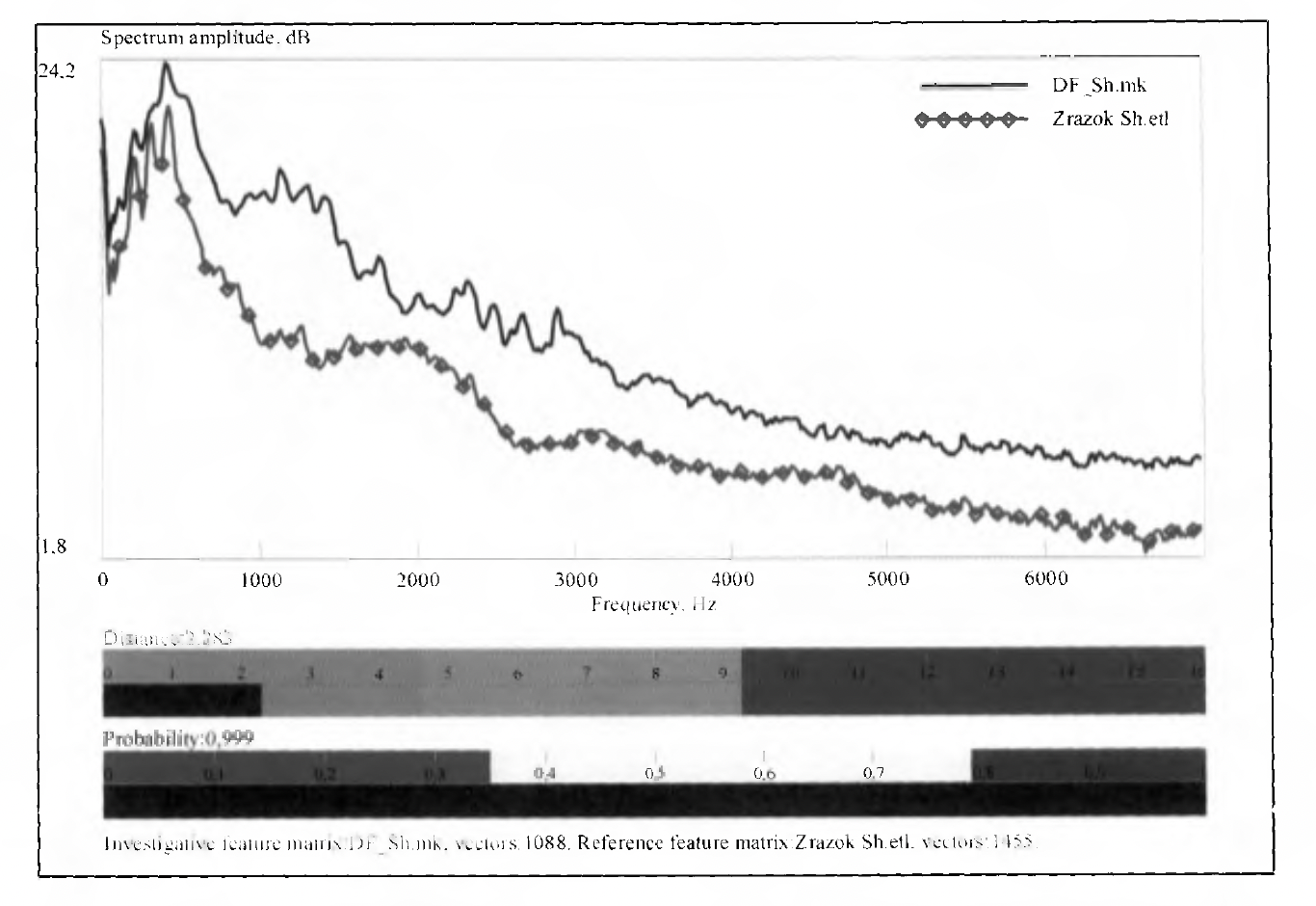
Що відбувається при побудові АЧХ всього файлу?
-
Графік буде містити сумарний спектр всіх звуків, які є у файлі.
-
Форманти, характерні для окремих голосних, будуть накладатися один на одного.
-
Спектр буде містити не лише голосні, а й приголосні, шуми, паузи, що можуть ускладнити аналіз.
Приклад:
Якщо у файлі вимовлено речення «Це тестовий запис», АЧХ покаже:
-
Спектр голосних [e], [o], [a], [i] — з їхніми формантами.
-
Спектр приголосних (які мають менше енергії, але все ще впливають на загальний спектр).
-
Шум (наприклад, фоновий або від дихання).
Чому це проблема для формантного аналізу?
-
Форманти різних голосних змішуються, і стає складно розрізнити, які частотні піки відповідають конкретним голосним.
-
Приголосні звуки мають інший спектр, що може спотворювати загальний вигляд АЧХ.
-
Якщо у файлі є різні голосні, вони мають різні формантні частоти, що може робити побудову єдиної формантної структури некоректною.
Аналогія:
Уявіть, що ви намагаєтесь зрозуміти смак окремих інгредієнтів у супі, але всі вони змішані. Визначити точні характеристики кожного компонента складніше, ніж якби вони були окремо.
Як правильно будувати АЧХ для формантного аналізу?
Щоб отримати коректні форманти, краще:
- Розбити запис на голосні звуки (наприклад, за допомогою спектрограм або вручну).
- Будувати АЧХ окремо для кожного голосного.
- Фільтрувати приголосні — їхній внесок у загальний спектр не такий важливий.
Методи покращення аналізу:
✔ Використання спектрограми — дозволяє побачити форманти в часі та виділити їх для конкретних голосних.
✔ Фільтрація частот — дозволяє прибрати шуми та виділити основні резонанси.
✔ Автоматичне розпізнавання голосних — нейромережі можуть автоматично розбивати сигнал на окремі голосні перед аналізом.
Для точного аналізу формант мовця потрібні окремі графіки АЧХ для кожної голосної. Оскільки кожен голосний звук має свою унікальну формантну структуру, їх не можна порівнювати без урахування конкретного звука. Для кожного запису для однієї і тієї ж букви одного мовця форманти можуть суттєво відрізнятися, але відстань між формантами є унікальною для кожної людини. Вона, ця відстань, і порівнюється для визначення мовця.
Але кого це все цікавить? Якщо намалювати дві криві, то для суду це достатньо. І для вироку теж.
Читайте також:
Блиск і злидні Sive Base Частина 2 (поміряємо що завгодно та щось порахуємо)
Блиск і злидні Sive Base (фоноскопічна експертиза). Частина 3
Блиск і злидні Sive Base (фоноскопічна експертиза). Частина 4 — остання